A Two-Part Approach to Understanding zk Coprocessors
2024-05-21
Zk Coprocessors can be divided into two types: data access zk Coprocessors, and computation zk Coprocessors [1]. Both use succinct proofs, but each is intended to solve a different type of problem. For data access zk Coprocessors, the problem is trust, whereas for computation zk Coprocessors, the problem is scalability.
The Problem - Trust
Data access zk Coprocessors represent relatively new technology enabling developers to access historical blockchain data trustlessly via zero-knowledge proofs. While blockchains function as public records with universal agreement on entries, the counterintuitive challenge emerges when requiring trustless data retrieval. Most data accessed is historical—Ethereum blocks become historical within approximately 12 seconds, making trustless verification difficult without specialized technology.
As Axiom cofounder Yi Sun explained in a September 2023 interview:
"You basically have two options as a developer. One option, which is in principle trustless, is that every block of Ethereum commits to the entire history of Ethereum."
Yi explains the computational impracticality: developers either cache data anticipating future needs (which is expensive and requires knowing what data will be needed in advance) or rely on trusted oracles (which introduces trust assumptions that undermine decentralization goals).
Data access zk Coprocessors solve this by replicating Ethereum's block header validation logic to cryptographically prove that requested historical data was correctly included in specific blocks—without requiring trust in any third party.
The Problem - Scalability
Computation zk Coprocessors address the constraint that complex calculations may exceed Ethereum's computational budget and block space. Using SNARKs or STARKs, these systems enable off-chain execution while preserving decentralization and trustlessness.
The distinction from zk rollups is important [3]: rollups batch numerous transactions, whereas computation coprocessors prove arbitrary single calculations. As the saying goes, "a zk Rollup allows 10,000 people to send $5 each, whereas a computation zk Coprocessor allows one person to compute a forecast using a complex weather model."
The workflow involves:
- User submits computation request to off-chain coprocessor
- Coprocessor executes the computation and generates a validity proof
- Verifier smart contract validates the proof on-chain
Most computation coprocessors employ universal verifiers—smart contracts capable of validating any circuit by accepting the circuit itself as compressed input, similar to universal Turing machines.
Differing Models of Computation, Differing Levels of Accessibility
SNARKs don't prove program execution directly but rather satisfy a set of constraints representing an arithmetic circuit. This creates accessibility challenges, as circuit engineers must use domain-specific languages (DSLs) to write constraints—a significant barrier for most developers.
There are three approaches to bridging the gap between traditional programming and arithmetic circuits, ordered from "most like a circuit" to "most like a program":
Libraries
Developers still write circuits but get "shortcuts" through modularized constraint sets. Axiom SDK exemplifies this approach. While this maintains fine-grained optimization control, it still requires understanding of circuit design. Loops, branching, and compile-time input specification remain restricted.
Domain-Specific Programming Languages
Tools like ZoKrates allow developers to write in domain-specific languages that compile to circuit constraints. This sacrifices some optimization capability for simplicity, but these DSLs often lack the mature ecosystems of general-purpose languages.
zkVM-Compiled Programs
Developers write in general-purpose languages (TypeScript, Rust), and a zero-knowledge virtual machine abstracts away constraint generation entirely. ORA and RISC Zero use this approach. The tradeoff is reduced performance optimization but guaranteed circuit constraint satisfaction once VM opcodes are audited.
As an example, the following diagram represents the ladder of abstraction of zero knowledge proof systems. At the lowest, most fundamental level, a SNARK or STARK is either a small set of elliptic curve elements or hashes. In systems with a zkVM, the highest level is developer source code written in a high-level programming language; in systems without a zkVM, the highest level is an arithmetic circuit representing a specific computation.
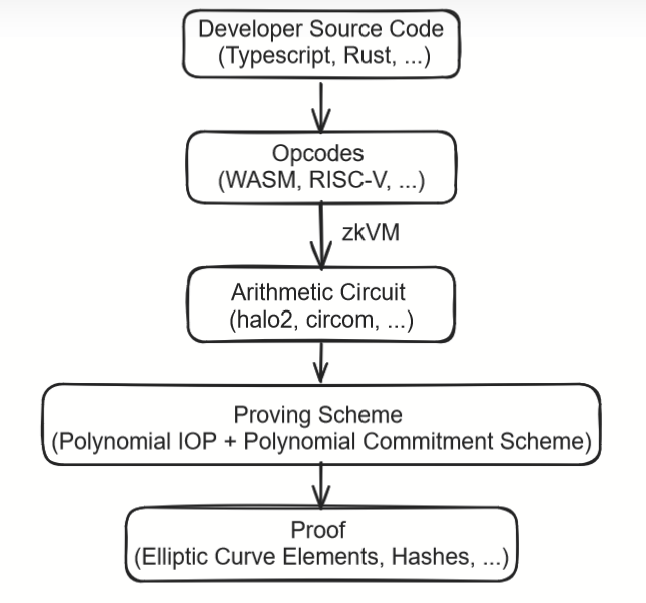
If the most important factor is performance, then hand-written circuits are better, as the developer can optimize them "by hand." If the most important factor is accessibility, then zkVMs are better, as they allow developers to write in familiar programming languages.
Protocol Comparisons
Axiom
Axiom is a data and computation coprocessor using halo2-lib with Plonkish arithmetization [5].
Developer Experience: TypeScript SDK with three-step workflow—trustless data retrieval, client circuit design, smart contract integration. Built-in mathematical operations simplify circuit writing but control flow requires multiplexers. Developers still need to understand circuit design principles.
Specifications:
- Default query limit: 128 data pieces (expandable via partnership)
- Mainnet availability: January 22, 2024
- Status: Core contracts and circuits audited
- Proving system: halo2 (Plonkish)
- Performance strength: Excellent for small-to-medium circuits
Use Case: Developers proficient in Solidity/TypeScript seeking high-performance solutions with limited historical data access requirements.
ORA (formerly HyperOracle)
ORA is a zkOracle network combining data access, computation, and zkAutomation (conditional on-chain posting) [6].
Developer Experience: Developers write Computational Logical Entities (CLEs) in TypeScript/AssemblyScript using cle-lib for trustless data retrieval. Programs compile to WebAssembly, then to halo2 circuits via zkWASM (Delphinus Labs backend). Compatible with Graph protocol subgraphs.
Specifications:
- Proving scheme: halo2-pse with Plonk and KZG
- Proof generation: ~40 seconds per computation (February 2024)
- Community adoption: 30+ community-built CLEs (January 2024)
- Current limitation: Mainnet data source only; zkAutomation unavailable on mainnet
Use Case: TypeScript-proficient developers wanting straightforward program-based verification or AI integration without learning circuit design.
Proxima One: Maru
Maru is specialized for large-dataset computation using Merkle mountain ranges and recursive STARK proofs [7] [8].
Developer Experience: Developers write Solidity contracts with added Ethereum data access functions. GitHub repository linking triggers automatic circuit compilation. The proving system is Starky (Plonky2 adaptation with cross-table lookups and fast recursion).
Performance Benchmarks (Keccak-256 circuits):
- Setup: Axiom superior for inputs under 28KB; Maru superior for larger inputs
- Prover time: Axiom faster up to ~2KB; Maru faster above 2KB
- Proof size: Axiom consistently superior
- Verification: Axiom generally faster
- Target: Sub-12-second proof generation
Use Case: Solidity developers computing over extensive Ethereum event datasets or large circuits where Maru's optimization for scale provides advantages.
RISC Zero (Bonsai)
RISC Zero is a zkVM based on RISC-V instruction set, recently released as Bonsai computation coprocessor [9].
Developer Experience: Developers write Rust programs (C++ and any RISC-V compilable language supported, but Rust-focused). RISC Zero zkVM compiles RISC-V opcodes to arithmetic circuits, eliminating manual constraint writing entirely.
Notable Achievement: Zeth (zkEVM proving Ethereum block validity) was developed in just four weeks using Bonsai [10], leveraging Rust crate portability and revm library code reuse. Achieved 50-minute block verification; estimated 9-12 minutes with GPU parallelism.
Status: Permissioned alpha access (February 2024); API key required.
Tradeoff Principle: Code reuse acceleration sacrifices low-level optimization and prover performance. This is ideal for rapid prototyping but may not achieve the performance of hand-optimized circuits.
Use Case: Rust developers bootstrapping large projects through ecosystem code reuse, prioritizing development speed over prover optimization.
Benchmarking Challenges
There are currently no standard benchmarks for comparing zk Coprocessors [4] due to the field's youth and differing proof statements across systems. Each protocol optimizes for different use cases, making direct comparison difficult. As the space matures, we expect standardized benchmarking methodologies to emerge.
Some Thoughts on the Future of zk Coprocessors
It is always a safe bet to predict that the current technology will improve, and zk Coprocessors are no exception to this rule. As performance continues to improve, zk Coprocessors will be used in a wider variety of decentralized applications. Improvements will occur at multiple abstraction levels, enabling wider adoption.
A critical milestone involves achieving prover time significantly below 12 seconds—which would enable real-time blockchain tracking. This would allow coprocessors to scan new blocks and submit proofs in near-real-time, opening entirely new categories of applications.
Two emerging areas warrant particular attention: AI and big data.
Greater integration of zk Coprocessors with verifiable AI will become a necessity for developers who want to use the problem-solving capabilities of AI in a way that is trustless and censorship-resistant. This convergence of zk proofs and AI represents a significant frontier.
Additionally, as analyzing large data sets has proven to be desirable in web2, it seems likely that verifiably doing so will be essential in web3. AI verifiably trained on large sets of blockchain data will provide verifiable inferences on that data, enabling new forms of on-chain intelligence with cryptographic verification guarantees.